Build Big Data Pipelines w Hadoop, Flume, Pig, MongoDB
This post was published 7 years ago. Download links are most likely obsolete. If that's the case, try asking the uploader to re-upload.
MP4 | Video: AVC 1280x720 | Audio: AAC 48KHz 2ch | Duration: 3.5 Hours | Lec: 46 | 470 MB | Language: English + Sub .VTT
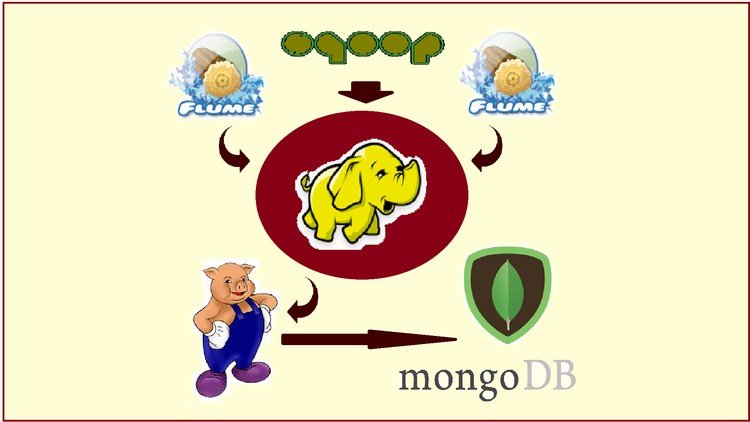
Learn how to combine Hadoop, MongoDB, Pig, Sqoop and Flume to Architect and Build Big Data Pipelines and Data lakes.
What you'll learn
Learn how to stitch individual Big Data Technologies together to solve business problems
Build and deploy Big Data Pipelines
Requirements
Hadoop
Linux / CDH 5
Java Programming preferreddobe Photoshop is Recommended
Description
How do you build end-to-end Big Data Pipelines using multiple Big Data Technologies? You have seen courses and books that teach you individual technologies, but how do you combine and apply them to solve your business problems? This course teach you exact that !
Building Big Data Solutions require you to acquire data from multiple sources, transport them, process them and store them in Big Data repositories. You have to do that with scalability and reliability. Big Data Technologies like Hadoop, Sqoop, Pig, Flume etc. solve individual problems, but building an end-to-end solution requires stitching them together. This course teaches you how to do that. You solve complete business problems by building end-to-end pipelines in this course.
Who this course is for?
Big Data Engineers
Big Data Architects
Homepage
Screenshots

**If you want to buy or renew premium account , Please buy from below links and support me**
=> visit my blog for more courses: DazX Blog
Quick check before we show the links
Helps us keep automated scrapers from hammering the filehosts.